
|
Over the past few years the MQTT protocol has taken industrial automation by storm. Although it's a mature protocol, I feel that it's still not very clear to most people exactly what MQTT does.
This post is targeted to those who've heard about MQTT and want some more information on what it does, and doesn't, do. Our SCADASuite product does have an MQTT application, but I wouldn't describe ourselves as evangelists. There's a lot of good things about MQTT, but it's certainly not the cure-all that it's often touted as. 
Introduction MQTT was first released in 1999, so it's been around for a while. Its main purpose is to allow low power and resource constrained devices to send and recieve data. It's almost always used on top of TCP/IP, although, strictly speaking, other types of transport can be used. 
Interoperability
MQTT allows for interoperability at the transport layer, but has no protocol specific payload. This means that different devices that exchange data using MQTT, but there's no guarantee that the data that they exchange makes sense to one another. Put another way, MQTT is useful moving a bucket of bits from one place to another, but theres no standard on what those bits mean, which means that there's really no 'out of the box' interoperability between devices from different vendors, unlike with common industrial protocols like Modbus or DNP3. Cirrus Link's SparkPlug format is an effort to increase interoperability when using MQTT. It specifies a payload format so that all devices know how to interpret the transmitted data. Sparkplug is built using Google's proven protocol buffers (protobufs) serialization technology. Sparkplug is specific .proto implementation that has support for pretty much any type of industrial data that a device would want to send, including tabular, non-numeric and historic data. Sparkplug isn't just a payload format, however. It also includes features like node birth and death, device birth and death, clean disconnects, and others. These features facilitate advanced functionality like automatic tag generation when using Inductive Automation's Ignition SCADA product, but muddy the waters between what the protocol does, and what the payload does. The use of protobufs as a payload format raises an interesting question: Why use MQTT at all if protobufs formatted data can be used with just TCP/IP transport? There are good reasons to use MQTT, of course, but sometimes it might make sense to just ship your protobufs using TCP/IP. 
Security and Encryption
MQTT has support for authentication starting with version 3.1.1, which was released in 2014. Authentication allows sending a username and password from the device to the broker when an MQTT connection is initialized. Credentials are sent in plain text unless transport encryption like TLS is used. MQTT is most almost always used on top of TCP/IP transport, and TCP/IP supports encrypted connections using TLS, so all of the features of TLS are available, including advanced features like Mutual TLS (mTLS). VPNs, private APNs, virtual LANs and other security-centric features can also be used without any problems. The security story for MQTT is quite a bit better than for legacy protocols like Modbus. However, once you add TLS and VPN and mTLS, your lightweight M2M communications story starts looking a bit more heavy. 
Publish/Subscribe
The biggest difference between MQTT and other industrial protocols like Modbus or DNP3 is the the fact that MQTT uses a publish/subscribe model instead of a client/server model. All MQTT messages are published to a broker. Devices that want to listen for messages subscribe to topics on the broker, and when the broker receives a message on that topic, it pushes it out to whoever is subscribing. In this way, data from a device is made available to multiple systems. There's no question that using a pub/sub model allows data to make it's way to different clients easily, but it often comes with quite a bit of complexity that's not immediately obvious. For example, the system always needs a broker, which is single point of failure. In a high reliability system, multiple brokers are needed, and some fail over mechanism is needed for both publishers and subscribers to know which broker is active at any time. Adding control, where field devices subscribe to topics, makes this even more complex. Any device that has access to an MQTT namespace can publish a new value to a topic. All of the devices that are subscribed to that topic will get an update, which is great. But, from a security and auditing standpoint, it's sometimes not obvious where the change came from and why it was made, since so many different clients can be subscribed to a topic. On the whole, traditional automation systems and the client server model are conceptually simpler, and it's obvious to understand how data is moving. Pub/sub is great for getting data to different clients, but there's no technical reason why this can't be implemented just as easily with traditional industrial automation systems. Even if you want to use MQTT, is the correct place for the MQTT broker in between the field devices and SCADA server, or on the back end of the SCADA server? Using the second approach still allows you break data out to multiple clients, but with the security and auditability of knowing that only the SCADA system will actually communicate with field devices. 
Communications Efficiency
MQTT uses communications bandwith very efficiently. Because data is pushed from devices, and not polled from a master, data only needs be sent when a value changes. This also leads to a responsive system, where changes are seen immediately, instead of waiting for the next scheduled poll. These features are not exclusive to MQTT, however, and can be found in industrial protocols like DNP3. 
Final Thoughts
MQTT is certainly a useful protocol with many interesting features. However, it's no panacea, and implementation must be considered carefully. It's much more important to first think about the requirements of your system - how data should flow, where it's generated and where it's needed, and how it needs to be transformed to be useful. A protocol is not a solution, it's just once piece of a complex and ever changing puzzle. With the proliferation of cloud services, there are many different ways to move and transform data securely and reliably. An optimial data transport mechanism cannot be chosen in a vacuum, but only after your requirements are well understood.
0 Comments
I recently had an interesting conversation with a customer about galvanic isolation. They were using a current supply for cathodic protection, but the devices were breaking in the field. The solution from the vendor was to use an isolated DC/DC to the input of the current supply device. How does isolation solve the problem? If you look at the circuit below, there's no reason isolation would be required. Power comes into the DC/DC converter, and then the current source pushes current through the load. 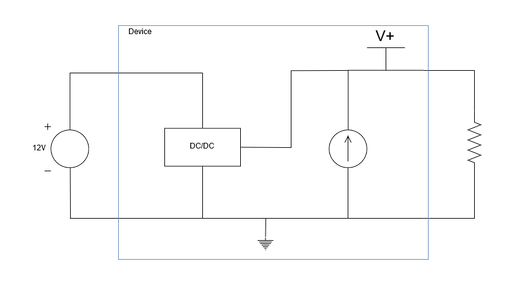 Simple current source The schematic hides the details of the current source circuit, but the details are important to understand why this doesn't work.
In both current source circuits, the load is not connected to ground. It has to be connected to an internal point within a circuit. If the bottom side of the load is connect to ground, then a short circuit to ground occurs. Current through the load resistor flows directly to ground, and bypasses the control circuitry. 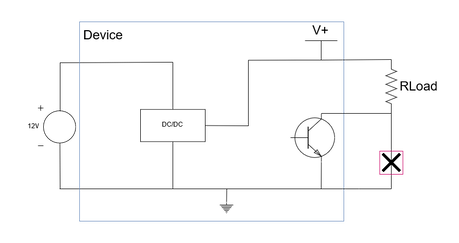 Short circuit Isolation breaks the ground loop and forces current to be returned through the current source, instead of to the power source. 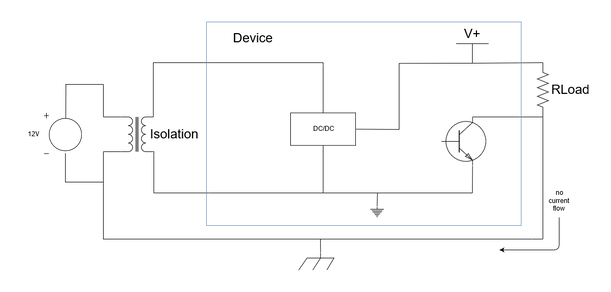 Isolation breaks the short circuit Although the example circuitry shown above is fairly simple, the same principles apply to more complex circuity. I recently designed a 4 to 20 mA current output using a Texas Instruments DAC161S997. The simplified schematic of this circuit is shown below. In the schematic, the DAC is loop powered. If the loop power is not isolated from the power input to the IC, then current will return to ground at the COMD/COMA pin, and not through LOOP-, which is wrong. 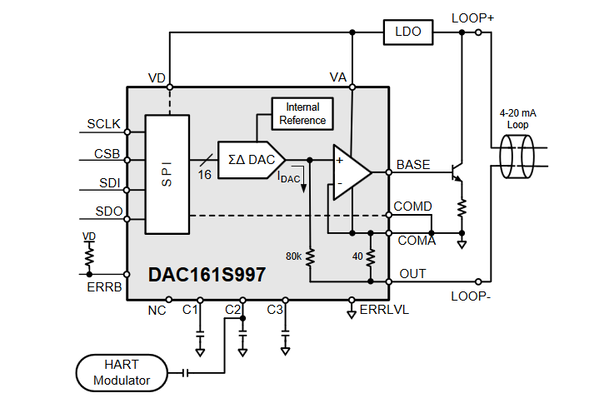 TI DAC161S997 simplified schematic |
SUMMARY
Commentary and insight on emerging trends and technology in industrial automation, along with whatever else catches our fancy. Archives
December 2019
Categories
|

 RSS Feed
RSS Feed
